데이터 무결성과 보호[1]#
디스크 오류 모델#
RAID(Redundant Array of Independent Disks)에 대해 배웠던 장에서 알 수 있듯이, 디스크는 완벽하지 않으며 때로는 오류가 발생할 수 있습니다. 초기 RAID 시스템에서는 오류 모델이 비교적 단순했습니다. 디스크는 완전히 작동하거나 완전히 작동하지 않는 두 가지 상태만 있다고 가정했기 때문입니다. 이렇게 디스크의 고장을 쉽게 감지할 수 있는 특성을 실패 시 정지(fail-stop) 모델이라고 하며, 이 모델 덕분에 RAID 구현이 그리 어렵지 않았습니다.
그러나 실제로는 디스크에서 두 가지 종류의 단일 블록 오류가 자주 발생합니다. 하나는 잠재적 섹터 오류(Latent Sector Error, LSE)이고 다른 하나는 블록 손상(Block Corruption)입니다. 이제 이 두 오류에 대해 자세히 알아보겠습니다.
LSE는 디스크의 특정 섹터나 섹터 그룹이 어떤 이유로 손상되었을 때 발생합니다. 예를 들어, 디스크 헤드가 표면에 닿아서 (이를 헤드 크래시(head crash)라고 하며 정상적인 상황에서는 발생하면 안 됨) 디스크 표면이 손상되면 해당 부분의 비트를 읽을 수 없게 됩니다. 강한 방사선 또한 비트를 반전시켜 데이터를 왜곡시킬 수 있습니다.
다행히도 대부분의 디스크는 ECC(Error Correcting Codes)를 사용하여 디스크 블록의 비트 무결성을 검사하고 경우에 따라 오류를 복구할 수 있습니다. 그러나 비트 상태가 좋지 않아서 ECC로도 복구할 수 없는 경우, 디스크는 해당 블록을 읽으려는 요청에 오류를 반환합니다.
반면에 블록 손상은 디스크가 손상 여부를 인식하지 못한 채 데이터가 훼손되는 경우입니다. 이때는 잘못된 내용의 블록이 정상적으로 읽혀지게 됩니다. 예를 들어 디스크 펌웨어의 버그로 인해 잘못된 위치에 데이터를 썼다면, 디스크의 ECC는 문제가 없다고 판단하겠지만 사용자가 나중에 해당 블록을 읽으면 엉뚱한 내용이 반환될 것입니다. 전송 버스의 오류로 인해 호스트에서 디스크로 전송되는 도중 블록이 손상될 수도 있고, 그 손상된 데이터가 디스크에 그대로 저장될 수 있습니다.
이런 블록 손상 오류를 무음 오류(silent fault)라고도 하는데, 디스크가 아무런 문제를 알리지 않은 채 잘못된 데이터를 반환하기 때문에 LSE보다 더 심각한 문제로 여겨집니다.
그렇다면 이 두 종류의 오류는 실제로 얼마나 자주 발생할까요? Bairavasundaram 등이 수행한 두 연구에서 관찰된 결과를 요약해 보겠습니다. 아래 표는 연구 기간 동안 적어도 하나 이상의 LSE나 블록 손상이 발생한 드라이브의 비율을 보여줍니다.
에러 유형 |
저가 드라이브 |
고가 드라이브 |
|---|---|---|
LSE |
9.4% |
1.4% |
블록 손상 |
0.5% |
0.05% |
저가 드라이브보다 고가 드라이브를 사용하면 이 두 가지 문제의 발생 빈도를 크게 줄일 수 있음을 알 수 있습니다. 하지만 여전히 무시할 수 없는 수준으로 오류가 발생하고 있으므로, 스토리지 시스템 설계 시 이를 고려해야 합니다.
LSE에 대한 연구에서는 다음과 같은 특징이 발견되었습니다.
LSE가 발생한 고가 드라이브는 저가 드라이브와 비슷한 수준으로 추가 오류를 만들어냅니다.
대부분 드라이브의 연간 LSE 발생률은 2년차에 증가합니다.
LSE 발생률은 디스크 용량에 비례하여 증가합니다.
LSE가 발생한 대부분의 디스크는 50개 미만의 LSE를 보유합니다.
한 번 LSE가 발생한 디스크는 추가로 LSE가 더 발생할 가능성이 높아집니다.
LSE는 공간적, 시간적 지역성(locality)을 보입니다.
전체 디스크 스크러빙(disk scrubbing)이 LSE 탐지에 효과적입니다.
블록 손상에 대해서는 다음과 같은 특징이 관찰되었습니다.
같은 등급의 드라이브라도 모델에 따라 블록 손상 발생 확률이 크게 다릅니다.
사용 기간에 따른 영향은 드라이브 모델마다 다르게 나타납니다.
워크로드나 디스크 용량은 블록 손상 빈도에 큰 영향을 미치지 않습니다.
블록 손상이 발생한 디스크 대부분은 손상된 블록을 소수만 가지고 있습니다.
RAID 그룹 내 디스크들의 블록 손상이나 단일 디스크 내 블록 손상은 독립적이지 않습니다.
LSE 발생과는 연관성이 크지 않습니다.
이 주제에 대해 더 자세히 알고 싶다면 관련 논문을 직접 읽어보시기 바랍니다. 어쨌든 신뢰할 수 있는 스토리지 시스템을 만들기 위해서는 반드시 LSE와 블록 손상을 탐지하고 복구하는 기술을 갖추어야 할 것입니다.
잠재적 섹터 오류(Latent Sector Errors)#
그럼 이제 디스크의 부분 오류 두 가지에 대한 대응 방안을 알아보겠습니다. 먼저 다루기 쉬운 잠재적 섹터 오류(LSE)부터 시작하죠.
사실 LSE는 쉽게 감지할 수 있기 때문에 그리 어렵지 않게 해결할 수 있습니다. 스토리지 시스템이 특정 블록에 접근하려 할 때 디스크에서 오류를 반환한다면, 중복 정보를 이용해서 어떻게든 올바른 데이터를 복구해 내면 됩니다. 예를 들어 미러링 RAID에서는 미러 사본에서 데이터를 가져올 수 있고, RAID-4나 RAID-5 같은 패리티 기반 시스템에서는 패리티 그룹 내 다른 블록들로부터 데이터를 재구성할 수 있습니다.
즉, LSE처럼 감지하기 쉬운 오류에 대해서는 널리 알려진 중복 방식들을 통해 쉽게 복구할 수 있는 것입니다.
LSE가 점점 더 빈번해지면서 지난 몇 년간 RAID 설계에도 변화가 있었습니다. RAID-4/5 시스템에서 발생 가능한 흥미로운 문제 중 하나는, 한 디스크가 완전히 고장 나는 동시에 다른 디스크에서 LSE가 발생하는 것입니다.
디스크 한 개가 완전히 고장 나면 RAID는 패리티 그룹 내 모든 나머지 디스크를 읽어서 손실된 데이터를 재구성합니다. 그런데 재구성 도중 다른 디스크에서 LSE가 발생하면 재구성이 실패하게 되는 거죠.
이 문제에 대응하기 위해 몇몇 시스템들은 추가적인 방법을 도입했습니다. 예를 들어 NetApp의 RAID-DP는 패리티 디스크를 두 개 사용합니다. 재구성 중 LSE가 발생해도 추가 패리티 정보를 이용해 복구를 마칠 수 있습니다.
물론 추가 패리티 디스크를 두는 것은 상당한 비용이 드는 일입니다. 하지만 NetApp의 WAFL 파일 시스템은 로그 구조를 채택함으로써 그 비용을 여러 방면에서 상쇄하고 있습니다. 결과적으로 추가 패리티 블록에 필요한 디스크 공간만이 실질적인 비용으로 남게 됩니다.
손상 검출 : 체크섬#
이제 데이터 손상을 통한 조용한 오류의 문제에 대해 알아봅시다. 어떻게 사용자가 손상된 데이터를 받는 일을 방지할 수 있을까요?
숨은 섹터 에러와 달리, 손상 문제에서는 검출이 핵심 문제입니다. 어떻게 알 수 있을까요? 일단 알기만 한다면 복구는 이전과 같이 이뤄질 수 있습니다. 해당 블럭의 다른 복제본을 어딘가에 저장해놓고 쓰는 것입니다.
현대 스토리지 시스템에서 데이터 무결성을 지키기 위해 쓰는 주 메커니즘은 *체크섬(checksum)*이라 불리는 것입니다. 체크섬은 데이터 청크를 입력으로, 해당 데이터의 내용의 작은 요약본을 출력하는 함수의 결과입니다. 이러한 계산의 목표는 데이터 체크섬을 저장해놨다가 나중에 해당 데이터에 대한 요청이 들어왔을 때 계산한 체크섬이 원래의 값과 일치하는지를 확인함으로써, 시스템이 데이터가 어떻게든 손상되거나 바뀌었는지를 확인하는 것입니다.
널리 사용되는 체크섬 함수#
체크섬 계산을 위해 쓰이는 함수에는 여러 가지가 있는데, 그 강도와 스피드에서 차이를 보입니다. 보호성이 높으면 비용도 커지는, 시스템에서 흔히 보이는 트레이드 오프가 여기서도 나타납니다.
한 가지 간단한 체크섬 함수로는 XOR을 사용하는 것이 있습니다. XOR 기반 체크섬에서, 체크섬은 데이터 블럭의 각 청크들을 XOR함으로써 하나의 값을 만들어 냄으로써 계산됩니다.
16바이트 블럭에 대해 4바이트 체크섬을 계산하려고 한다고 해봅시다. 16바이트의 데이터는 16진법으로 다음과 같다고 합니다.
365e c4cd ba14 8a92 ecef 2c3a 40be f666
이진법으로 보면 다음과 같습니다.
0011 0110 0101 1110 1100 0100 1100 1101
1011 1010 0001 0100 1000 1010 1001 0010
1110 1100 1110 1111 0010 1100 0011 1010
0100 0000 1011 1110 1111 0110 0110 0110
각 열에 대해 XOR을 수행했을 때의 최종 체크섬 값은 다음과 같습니다.
0010 0000 0001 1011 1001 0100 0000 0011
16진법으로는 0x201b9403입니다.
XOR은 쓸 만하지만 한계도 있습니다. 예를 들어 두 데이터 청크의 같은 위치에 있는 두 비트가 모두 바뀌는 경우, 체크섬을 통해서는 데이터 손상을 탐지할 수 없게 됩니다. 이러한 이유로 사람들은 다른 체크섬 함수들을 만들어냈습니다.
다른 기초적인 체크섬 함수에는 덧셈이 있습니다. 이 방식은 빠르다는 장점을 가지고 있습니다. 데이터의 각 청크에 대해, 오버플로를 무시하고 2의 보수 덧셈을 수행하면되기 때문입니다. 이 기법은 많은 데이터 변경을 찾아낼 수 있지만, 데이터가 시프트된 경우에는 잘 검출해내지 못합니다.
조금 더 복잡한 알고리즘은 Fletcher checksum이라 불리는 것입니다. 계산은 간단한데, 체크 바이트 \(s_1\),\(s_2\) 를 이용합니다. 구체적으로, 블럭 \(D\) 가 바이트 \(d_1\),…,\(d_2\) 으로 이루어져 있습니다고 합시다. \(s_1\) 과 \(s_2\) 는 각각 다음과 같이 정의됩니다.
Fletcher checksum은 거의 CRC만큼이나 강력해서, 모든 단일 비트, 두 비트 에러들도 찾아내고 그 외의 많은 에러들도 찾아냅니다.
마지막으로 자주 쓰이는 체크섬으로는 *순환 중복 검사(cyclic redundancy check, CRC)*가 있습니다. 데이터 블럭 \(D\) 의 체크섬을 계산하려고 한다고 해봅시다. 이제 할 것은 그냥 \(D\) 를 큰 이진수로 보고, 이를 합의된 값 \(k\) 로 나누는 것입니다. 이 나눗셈의 나머지가 CRC 값이 됩니다.
어떤 방법을 쓰든지 완벽한 체크섬은 없습니다. 서로 같지 않은 데이터 블럭들이 같은 체크섬을 가질 수도 있습니다(충돌, collision). 따라서 좋은 체크섬 함수를 정하려면, 이러한 충돌 가능성을 줄이면서도 계산하기 쉬운 방법을 찾아야 합니다.
Checksum Layout#
체크섬을 어떻게 계산하는지 알게 됐으니, 이제는 체크섬을 스토리지 시스템에서 어떻게 사용할지를 봅시다. 다뤄야 할 첫 번째 문제는 체크섬이 어떻게 디스크에 저장되어야 하는지에 대한 것입니다.
가장 기본적인 방식은 체크섬을 각 디스크 섹터, 혹은 블럭에 저장하는 것입니다. 데이터 블럭 \(D\) 에 대해, 그 체크섬을 \(C(D)\) 라 부르도록 합시다. 체크섬이 없는 경우 디스크 레이아웃은 다음과 같습니다.

체크섬을 이용하면 다음과 같이 각 블럭에 하나의 체크섬이 추가됩니다.

다만 위와 같은 레이아웃을 만드는 데 문제가 하나 발생합니다. 보통 체크섬은 작고(8바이트), 디스크는 섹터 사이즈(512바이트), 혹은 그 배수의 청크들에만 쓸 수 있기 때문입니다. 한 가지 해결법은 드라이브 제조사에서 체크섬의 크기를 더한, 예를 들면 520바이트 섹터를 만드는 것입니다.
그런 기능이 없는 디스크들의 경우에는 파일 시스템이 어떻게 체크섬을 저장할지를 결정해야 합니다. 한 가지 가능한 방법은 다음과 같습니다.

이 방식에서 n개의 체크섬은 하나의 섹터에 함께 저장되고, 그 뒤에는 n개의 데이터 블럭들이 저장됩니다. 이 방법은 모든 종류의 디스크에 적용할 수 있지만, 조금 덜 효율적일 수 있습니다. 만약 파일 시스템이 블럭 \(D1\) 을 덮어 쓰고 싶은 경우, \(C(D1)\) 이 있는 섹터를 읽고, 그 안의 \(C(D1)\) 을 갱신하고, 체크섬 섹터와 새 데이터 블럭 D1을 써야 합니다. 이와 달리 각 섹터에 체크섬의 자리가 마련된 앞의 경우는 한 번만 쓰면 됩니다.
체크섬의 활용#
위와 같이 체크섬 레이아웃이 정해졌다면, 어떻게 체크섬을 사용할지에 대해 알아봅시다. 블럭 D를 읽을 때, 클라이언트(파일 시스템, 혹은 스토리지 컨트롤러)는 저장된 해당 블럭의 체크섬 \(C_s(D)\) 도 읽습니다. 이후 클라이언트는 블럭 \(D\) 의 체크섬 \((C_c(D))\) 을 계산하고, 두 체크섬을 비교합니다. 만약 그 둘이 같으면 데이터가 손상되지 않은 것이라 판단하고 사용자에게 해당 데이터를 반환하고, 그렇지 않다면 데이터가 저장된 시점 이후에 변경되었다는 말입니다. 이 경우 데이터 손상이 일어나 것이라 할 수 있습니다.
그렇다면 손상이 일어난 경우에는 뭘 해야할까? 만약 스토리지 시스템이 중복 복제본이 있습니다면 나머지 복제본을 사용하면 됩니다. 만약 그런 복제본이 없다면? 에러를 반환합니다. 어떤 경우든, 손상 여부를 검출했다고 해서 모든 일이 풀리는 것은 아닙니다. 손상되지 않은 데이터를 얻을 길이 없다면 운이 없다고 생각합시다.
새로운 문제 : 잘못된 위치에 기록#
일반적인 경우 위의 기본 방식은 손상된 블럭들에 대해 잘 작동하지만, 현대 디스크들은 다른 해결법이 필요한, 흔치 않은 오류 모델들도 가지고 있습니다.
첫 번째 오류 모델은 misdirected write라 불린다. 이는 디스크나 RAID 컨트롤러에서, 제대로 된 데이터를 다른 위치에 쓰는 경우 일어납니다. 예를 들면 단일 디스크 시스템에서 주소 \(x\) 에 쓰여야 하는 데이터 블럭 \(D_x\) 를 주소 \(y\) 에 쓰는 경우가 그렇습니다. 다중 디스크 시스템에서는 디스크 \(i\) 의 주소 \(x\) 에 써야하는 데이터를 디스크 \(j\) 에 쓰는 경우도 있습니다. 그렇다면 어떻게 이런 문제를 검출할 수 있을까요? 체크섬 이외로 필요한 것에는 무엇이 있을까요?
놀랍게도 해결법은 간단합니다. 각 체크섬에 약간의 추가 정보들을 더하는 것입니다. 이 경우 *물리 식별자(physical identifier)*를 추가하는 게 도움이 됩니다. 예를 들어 저장된 정보가 체크섬과 더불어 디스크와 블럭의 섹터 번호도 가지고 있습니다면, 특정 위치에 제대로 된 정보가 들어있는지를 확인할 수 있습니다. 구체적으로 만약 클라이언트가 디스크 10의 블럭 4를 읽는 경우 \((D10.4)\), 저장된 정보는 디스크 번호와 섹터 오프셋도 포함합니다. 만약 정보가 일치하지 않으면, 잘못된 위치에 쓴 것이 되므로 데이터 손상이 검출됩니다.
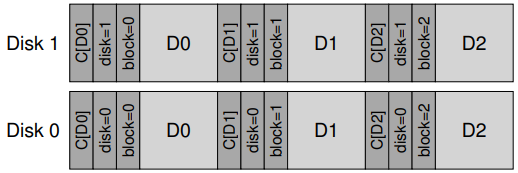
이제 디스크에 많은 중복 정보들이 포함되었음을 볼 수 있습니다. 각 블럭에 디스크 번호가 각 블럭에서 반복되고, 블럭의 오프셋도 해당 블럭에 들어있습니다. 이런 중복 정보들이 에러 검출과 복구의 핵심입니다. 약간의 추가 정보들을 통해 일어날지도 모르는 문제적 상황들을 찾아낼 수 있게 됩니다.
마지막 문제 : 기록 작업의 손실#
또 다른 문제도 있습니다. 구체적으로 몇몇 현대 저장 장치들은 lost write라 불리는 문제도 가지고 있습니다. 이는 장치가 상위 계층에는 쓰기 작업이 완료되었다고 알리면서도, 사실은 아무 것도 저장되지 않았을 때 발생하는 문제입니다. 이 경우 디스크에는 갱신되지 않은, 오래된 내용의 블럭만이 남게 됩니다.
문제는 이 경우, 위와 같이 체크섬이나 물리 ID를 사용하는 방법으로는 위 이슈를 발견할 수 없다는 것입니다. 그렇다면 이 문제는 어떻게 알아낼 수 있을까요?
가능한 해결법에는 여러 가지가 있지만, 한 가지 고전적인 방식으로는 쓰기 검증(write verify), 혹은 쓴 후 읽기(read-after-write)를 수행하는 것입니다. 쓰기가 끝나면 바로 해당 내용을 읽음으로써 시스템은 원하던 데이터가 디스크 표면까지 도달했는지를 확인하는 것입니다. 하지만 이 방식은 상당히 느립니다. 쓰기 작업을 완료하기 위해 필요한 I/O의 수를 두 배로 늘리기 때문입니다.
어떤 시스템들은 lost write를 찾기 위한 체크섬을 시스템 어디엔가 추가하기도 합니다. 예를 들어 Sun의 Zettabyte File System(ZFS)의 경우, 각 파일 시스템 아이노드 및 해당 파일에 포함된 모든 블럭의 간접 블럭에 체크섬을 추가합니다. 이렇게 하면 데이터 블럭에의 쓰기 자체가 손실되더라도 아이노드 내의 체크섬이 오래된 데이터와 맞지 않게 될 것이기 때문에 위와 같은 문제를 알아낼 수 있습니다. 아이노드와 데이터로의 쓰기가 동시에 모두 실패하는 경우에는 마찬가지의 문제가 발생할 수 있지만, 흔치는 않습니다
Scrubbing#
그렇다면 이 체크섬들이 실제로 확인되는 건 언제일까? 물론 어느 정도는 애플리케이션이 데이터에 접근할 때 일어날 수도 있지만, 이 경우 대부분의 데이터는 거의 접근되지 않기 때문에 확인되지 않은 채로 남게 됩니다. 확인되지 않은 데이터는 신뢰성 있는 스토리지 시스템에 문제가 될 수 있습니다. 조금의 흠이 전체 데이터에 영향을 줄 수도 있기 때문입니다.
이 문제를 해결하기 위해, 많은 시스템들은 *디스크 스크러빙(disk scrubbing)*을 이용합니다. 주기적으로 시스템 내 모든 블럭을 읽고 체크섬이 여전히 유효한지 확인함으로써, 디스크 시스템은 특정 데이터 아이템의 모든 복사본들이 손상되는 경우를 줄일 수 있게 됩니다. 보통의 시스템들은 매일 밤, 혹은 매 주 이러한 작업을 스케줄링 해놓습니다.
체크섬 오버헤드#
데이터 보호를 위한 체크섬 사용의 오버헤드에는 무엇이 있을까요? 두 가지가 있습니다. 공간과 시간입니다.
공간 오버헤드로도 두 가지가 있습니다. 첫 번째는 디스크 자체에 대한 것입니다. 각 저장된 체크섬은 디스크 내 공간을 차지합니다. 보통은 4KB 데이터 블럭에 대해 8바이트 체크섬을 사용하고, 0.19%의 디스크 공간 오버헤드가 발생합니다.
다른 종류로는 시스템 메모리에서 발생합니다. 데이터에 접근할 때, 이제는 데이터 뿐만 아니라 체크섬을 위한 공간도 필요합니다. 하지만 만약 시스템이 단순히 체크섬을 확인하고 이후 버린다면, 이러한 오버헤드는 오랫동안 유지되지는 않기 때문에 크게 걱정할 일이 아닙니다. 오직 체크섬이 메모리에 남는 경우에만 이 작은 오버헤드는 영향을 주게 됩니다.
이렇듯 공간적 오버헤드는 작지만, 체크섬으로 인한 시간적 오버헤드는 상당합니다. 적어도 CPU는 데이터를 쓰거나 읽을 때 각 블럭에 대한 체크섬을 계산해야 합니다. 이런 CPU 오버헤드를 줄이기 위해 많은 시스템들이 사용하는 방법은 데이터 복사와 체크섬 계산을 한 번에 처리하는 것입니다. 복사는 어쨌든 일어나야 하기 떄문에, 복사와 체크섬 계산을 함께 하는 것은 상당히 효과적입니다.
CPU 오버헤드 외에도 체크섬 방식에 따라 추가적인 I/O 오버헤드가 발생할 수 있는데, 특히 체크섬이 데이터와 별개로 저장되는 경우, 그리고 백그라운드 스크러빙을 수행해야 하는 경우 등이 있습니다. 전자의 경우는 설계를 통해 오버헤드가 줄어들 수 있고, 후자의 경우는 언제 스크러빙이 일어날지를 조정하는 등을 통해 줄어들 수 있습니다.
요약#
우리는 체크섬의 구현과 사용을 중심으로 저장 장치에서 데이터를 보호하는 기법을 소개하였습니다. 체크섬은 종류에 따라 서로 다른 종류의 오류를 해결합니다. 저장 장치가 발전하면서 여지이 새로운 오류의 종류가 생겨날 일입니다. 그러한 변화에 대응하기 위하여 기ᨦ과 연구자들은 기존 기법들을 근본적으로 재설계하거나 전혀 새로운 기법들을 개발해야 할지도 모릅니다.